只有27亿参数,微软发布全新Phi-2模型!一场AI技术革命正式启动!

出品 | CSDN(ID:CSDNnews)
先后和 OpenAI、Meta 牵手推动大模型发展的微软,也正在加快自家小模型的迭代。就在今天,微软正式发布了一个 27 亿参数的语言模型——Phi-2。这是一种文本到文本的人工智能程序,具有出色的推理和语言理解能力。

同时,微软研究院也在官方 X 平台上如是说道,“Phi-2 的性能优于其他现有的小型语言模型,但它足够小,可以在笔记本电脑或者移动设备上运行”。

Phi-2 的性能真能优于大它 25 倍的模型?
对于 Phi-2 的发布,微软研究院在官方公告的伊始便直言,Phi-2 的性能可与大它 25 倍的模型相匹配或优于。
这也让人有些尴尬的事,不少网友评价道,这岂不是直接把 Google 刚发的 Gemini 最小型号的版本给轻松超越了?

那具体情况到底如何?
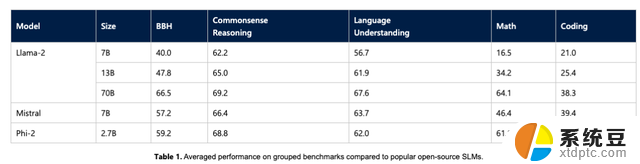
微软通过时下一些如 Big Bench Hard (BBH)、常识推理(PIQA、WinoGrande、ARC easy 和 Challenge、SIQA)、语言理解(HellaSwag、OpenBookQA、MMLU(5-shot)、 SQuADv2、BoolQ)、数学(GSM8k)和编码(HumanEval)等基准测试,将 Phi-2 与 7B 和 13B 参数的 Mistral 和 Llama-2 进行了比较。
最终得出仅拥有 27 亿个参数的 Phi-2 ,超越了 Mistral 7B 和 Llama-2 7B 以及 13B 模型的性能。值得注意的是,与大它 25 倍的 Llama-2-70B 模型相比,Phi-2 还在多步推理任务(即编码和数学)上实现了更好的性能。
此外,如上文所提及的。微软研究人员也直接在基准测试中放上了其与Google 全新发布的 Gemini Nano 2 正面 PK 的结果,不出所料,Phi-2 尽管尺寸较小,但性能还是把 Gemini Nano 2 超了。

除了这些基准之外,研究人员似是在暗讽 Google 前几日在 Gemini 演示视频中造假一事,因为当时 Google 称其即将推出的最大、最强大的新人工智能模型 Gemini Ultra 能够解决相当复杂的物理问题,并且甚至纠正学生的错误。
事实证明,尽管 Phi-2 的大小可能只是 Gemini Ultra 的一小部分,但它也能够正确回答问题并使用相同的提示纠正学生。


微软的改进
Phi-2 小模型之所以有如此亮眼的成绩,微软研究院在博客中解释了原因。
一是提升训练数据的质量。Phi-2 是一个基于 Transformer 的模型,其目标是预测下一个单词,它在 1.4T 个词组上进行了训练,这些词组来自 NLP 和编码的合成数据集和网络数据集,包括科学、日常活动和心理理论等用于教授模型常识和推理的内容。Phi-2 的训练是在 96 个 A100 GPU 上耗时 14 天完成的。
其次,微软使用创新技术进行扩展,将其知识嵌入到 27 亿参数 Phi-2 中。
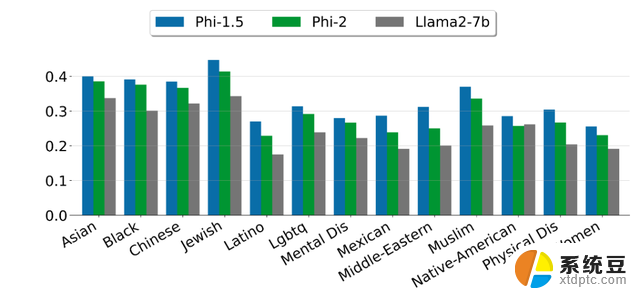
微软指出,Phi-2 是一个基础模型,没有通过人类反馈强化学习(RLHF)进行调整,也没有经过指导性微调。尽管如此,与经过对齐的现有开源模型相比,微软观察到在毒性和偏差方面,Phi-2 有更好的表现。

写在最后
话说 Phi-2 的发布的确在小模型的性能上实现了突破,不过也有媒体发现它还存在很大的局限性。
因为根据微软研究许可证显示,其规定了 Phi -2 只能用于“非商业、非创收、研究目的”,而不是商业用途。因此,想要在其之上构建产品的企业就不走运了。
来源:https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/

只有27亿参数,微软发布全新Phi-2模型!一场AI技术革命正式启动!相关教程
- 微软发布PowerToys 0.76.1更新:修复FancyZones等模块问题最新版本发布!
- 消息指微软向InflectionAI支付6.5亿美元 获得AI模型授权,开启人工智能合作新篇章
- 乌鸦AI日报:文心一言用户数突破2亿,微软向G42投资15亿美元最新动态
- 微软发布Windows Holographic 23H2版本,开启全新虚拟现实体验
- 未来城市规划中的全面电动化与数字货币:微软AI技术助力IPv6算力租赁
- 微软开发成本更低的人工智能,模仿OpenAI模型的质量达到新高
- 打脸了!微软竟然发布了自己的 Linux,开启全新操作系统时代
- 微软澄清:Win11 23H2要Q4才能发布,最新发布消息揭示了正式发布日期
- 微软投资1000亿美元推动生成式AI,这支股票有望大涨,投资者瞩目
- 微软向阿联酋人工智能技术公司G42投资15亿美元,加速人工智能技术发展
- 6大国产CPU中,有3大,已经胜出了?这3款处理器性能如何?
- 英伟达新一代AI芯片过热延迟交付?公司回应:客户仍然抢购
- 国产CPU厂商迎来新一轮竞争:谁将成为行业领头羊?
- 如何查看电脑显卡型号和性能信息的详细步骤:快速了解你的电脑性能
- 涉嫌破坏市场竞争 美国监管部门要调查微软云服务,引发关注
- 高通骁龙855处理器是旗舰处理器吗?你搞明白了吗?
微软资讯推荐
- 1 6大国产CPU中,有3大,已经胜出了?这3款处理器性能如何?
- 2 英伟达新一代AI芯片过热延迟交付?公司回应:客户仍然抢购
- 3 国产CPU厂商迎来新一轮竞争:谁将成为行业领头羊?
- 4 高通骁龙855处理器是旗舰处理器吗?你搞明白了吗?
- 5 如何激活Windows系统,轻松解决电脑激活问题,一键激活教程分享
- 6 千千纯净Win11的“了解此图片”图标的神秘功能: 提升系统安全性的关键利器
- 7 2024年11月值得入手的CPU,总有一款适合你的购买指南
- 8 告别Windows 10,迎接Windows 11的七大革新,抓紧升级!
- 9 在韩国组装PC市场,AMD拿下了62%的市场份额,成为最受欢迎的处理器品牌
- 10 超微放弃NVIDIA NVL72 GB200芯片订单,台湾公司接手大额订单
win10系统推荐
系统教程推荐
- 1 hp打印机如何开机 惠普打印机开机指南
- 2 苹果14云备份需要关闭吗 苹果iphone如何关闭iCloud自动备份
- 3 打印机设置双面打印怎么设置 打印机怎么设置双面打印
- 4 win11打印屏幕 怎么关闭 笔记本屏幕怎么关闭
- 5 怎么更换打开文件的方式 win10系统如何修改文件默认打开方式
- 6 win10开机通过microsoft登录 Win10系统怎么绑定Microsoft账户
- 7 笔记本怎么打开无线网络开关 笔记本wifi开关失灵怎么修复
- 8 matlab怎么调整字体大小 Matlab如何调整文字大小
- 9 怎么更改电脑设备名称 Windows10如何更改计算机名称
- 10 电脑显示器桌面字体如何调整 win10电脑字体设置步骤详解