AMD发布自家最强AI芯片:性能碾压H100,国内引入堪忧

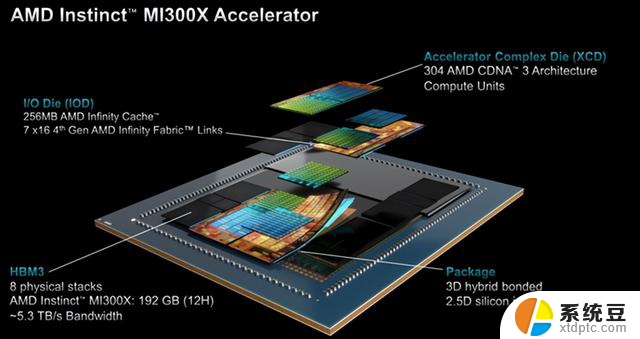
事实上,AMD在今年六月就纸面发布MI300A和MI300X。现在MI300A和MI300X已经开始批量量产了,所以在这次发布会上AMD也公布了更多关于MI300A、MI300X的性能数据。AMD MI300A采用了Chiplet设计,其内部拥有多达13个小芯片。基于台积电5nm或6nm制程工艺(CPU/GPU计算核心为5nm,HBM内存和I/O等为6nm),其中许多是3D堆叠的,以便创建一个面积可控的单芯片封装,总共集成1460 亿个晶体管。
MI300A采用新一代的CDNA 3 GPU架构,拥有228个计算单元(14592个核心),并集成了24个Zen 4 CPU内核,配置了128GB的HBM3内存。MI300A的计算核心被8个HBM3内存包围,单个HBM3的带宽为6.3GB/s,八个16GB堆栈形成128GB统一内存,带宽高达5.3 TB/s。 MI300A提供了高达61 TFLOPS FP64算力,多达122 TFLOPS FP32算力。

至于MI300X,内部集成了12个5/6nm工艺的小芯片(HMB和I/O为6nm),拥有1530亿个晶体管,采用了更多计算核心的CDNA 3 GPU。MI300X的每个基于CDNA 3 GPU架构的GCD总共有40个计算单元,相当于2560个内核。总共有八个计算芯片(GCD),因此总共有320个计算和20480个核心单元。不过,就目前的量产版而言,会稍微有一些缩水。
在内存带宽方面,MI300X也配备了更大的 192GB HBM3内存,带来高达5.2TB/s的带宽和896GB/s的Infinity Fabric带宽。大型内存池在LLM(大语言模型)中非常重要,LLM大多是与内存绑定的,AMD可以通过在HBM内存容量上的领先地位来提升人工智能能力。
具体来看性能提升,MI300A APU提供了相比H100高达4倍的性能提升,与NVIDIA的Grace Hopper超级芯片相比,该系统每瓦的性能也提高了2倍。而更像纯粹GPU架构的MI300X,在具体的AI大模型加速性能对比当中,相比H100在 FlashAttention-2 和 Llama 2 70B 中提供了高达 20% 的性能提升。在各种整数和浮点性能上,MI300X都是H100的1.3倍,这的确相当让人震惊。
AMD之前内部估计全球数据中心AI加速器市场在2023年的规模可达约300亿美元,今后每年的复合增长率都能超过50%,到2027年将形成超过1500亿美元的价值。而现在AMD已经将2023年、2027年的数据中心AI加速器市场规模预期分别调高到400亿美元、4500亿美元,年复合增长率超过70%。

从目前来看,针对AI市场,AMD拿出了比NVIDIA更全面的方案,MI300A作为一个APU方案,实际上解决了很多厂商的问题,终端厂商只要采购MI300A就能自己推出OEM的AI PC;而在纯GPU方案上,MI300X现在也要强于H100不少,目前AMD要做的就是完善自己的生态,从而让更多厂商选择自己的芯片。当然无论是MI300A还是MI300X,其算力早就超过了美国出口管制的底线,所以这两款芯片大概率是没法在国内销售的。在美国商务部点名NVIDIA之后,AMD可能不会针对国内市场推出特供版。
AMD发布自家最强AI芯片:性能碾压H100,国内引入堪忧相关教程
- 微软发布自研AI芯片Azure Maia 100及Cobalt 100,引领人工智能领域创新
- AMD发布新显卡驱动:多项特性增强,性能提升明显
- AMD Ryzen 7 5700X3D 和 5000GT 芯片开始在欧洲销售:全面升级,超强性能!
- 消息称AMD最快2026年发布Zen 6处理器,兼容AM5插槽:全面升级性能,引领未来技术发展
- 国产CPU里程碑!龙芯3A6000今年Q4杀到:性能堪比10代酷睿
- AMD发布AI芯片股价却下跌,新品能否挑战英伟达?市场反应如何?
- 七部门共推AI芯片发展,中国市场或将失去NVIDIA
- 中国企业仍需NVIDIA,阉割八成性能的国产芯片无法遮羞
- 英伟达AI芯片设计缺陷或影响微软、谷歌和Meta发布时间
- 高通发布全球最强CPU,微软叛变,X86王国不稳
- 6大国产CPU中,有3大,已经胜出了?这3款处理器性能如何?
- 英伟达新一代AI芯片过热延迟交付?公司回应:客户仍然抢购
- 国产CPU厂商迎来新一轮竞争:谁将成为行业领头羊?
- 如何查看电脑显卡型号和性能信息的详细步骤:快速了解你的电脑性能
- 涉嫌破坏市场竞争 美国监管部门要调查微软云服务,引发关注
- 高通骁龙855处理器是旗舰处理器吗?你搞明白了吗?
微软资讯推荐
- 1 6大国产CPU中,有3大,已经胜出了?这3款处理器性能如何?
- 2 英伟达新一代AI芯片过热延迟交付?公司回应:客户仍然抢购
- 3 国产CPU厂商迎来新一轮竞争:谁将成为行业领头羊?
- 4 高通骁龙855处理器是旗舰处理器吗?你搞明白了吗?
- 5 如何激活Windows系统,轻松解决电脑激活问题,一键激活教程分享
- 6 千千纯净Win11的“了解此图片”图标的神秘功能: 提升系统安全性的关键利器
- 7 2024年11月值得入手的CPU,总有一款适合你的购买指南
- 8 告别Windows 10,迎接Windows 11的七大革新,抓紧升级!
- 9 在韩国组装PC市场,AMD拿下了62%的市场份额,成为最受欢迎的处理器品牌
- 10 超微放弃NVIDIA NVL72 GB200芯片订单,台湾公司接手大额订单
win10系统推荐
系统教程推荐
- 1 改ip地址win10 win10怎么设置wifi ip地址
- 2 win10只录电脑声音 win10录制电脑内部声音教程
- 3 win11任务栏上面的新建桌面怎么 win11怎么新建桌面快捷方式
- 4 win11怎么设置私密文件 Win11加密文档的详细设置方法
- 5 win11系统内存查看 Windows11内存条大小查看方法
- 6 win11电脑怎么看自身配置 Windows11怎么查看自己的电脑配置
- 7 如何解除打印机脱机状态 win11 打印机显示脱机状态怎么办
- 8 win11电脑双屏幕怎么操作 笔记本连接双显示器步骤
- 9 win11开应用弹通知 Win11弹窗频繁怎么办
- 10 win11设星期天为第一天 怎样调整习惯让一周的第一天变成星期一